3. Time and Order
순서란 무엇이고, 왜 중요할까요?
“순서란 무엇인가” 라는 질문은 무슨 의미 일까요 ?
애초에 왜 여기에 왜 빠져있는 걸까요? 왜 우리는 A 가 B 이전에 실행되었다는걸 신경 써야할까요? 왜 우리는 다른 주제에는 신경을 안쓸까요 ? 색깔 같은거?
글쎄, 친구, 일단 이에 답변하기 위해 분산 시스템을 다시 살펴보도록 합시다.
기억하고 있을지 모르겠는데, 분산프로그래밍을 복수의 컴퓨터를 활용해서 같은 문제를 해결하는 예술이라고 묘사했었습니다.
이것은, 사실, 순서에 대한 강박(obsession)의 가장주요한 내용입니다. 어떤 시스템이든 한 번에 하나의 작업만 할수있고, 연산들의 모든 순서를 생성하게 됩니다. 사람들이 하나의 문을 통해 지나다니는것처럼, 모든 연산은 잘 정의된 전처리와 후처리로 구성됩니다. 이것이 우리가 보존하기위해 노력하고 있는 기본적인 프로그래밍 모델입니다.
전통적인 모델은: 하나의 싱글 프로그램, 하나의 프로세스, 하나의 메모리 공간이 하나의 CPU 에서 도는 것입니다. 운영체제는 다중 CPU 와 다중 프로그램에 대한 사실들을 추상화하고, 많은 프로그램들이 실 제로 메모리를 공유하는 것을 추상화 합니다. 저는 스데디드 프로그래밍과 이벤트 기바 프로그래밍이 존재하지 않다고 얘기하지는 않았습니다; 이것은 단지 이것들이 “하나/하나/하나"모델들 위에서 특별하게 추상화 되어있다는 것을 이야기하고 있습니다. 프로그램들은 순서대로 실행되도록 쓰여지게 됩니다; 최 상위에서 시작하여, 아래로 점점 내려가게 됩니다.
속성으로서의 순서는 많은 주목을 받았는데, “정확함"을 정의하는 가장 쉬운방법이 “하나의 기계에서 작동하듯 동작한다” 이기 때문입니다. 그리고 이것은 모동 다음을 의미하는데 a) 우리는 같은 연산을 수행하고 b) 복수의 기계에서도 같은 순서로 실행한다.
순서를 보존하는 분산시스템의 장점은, (하나의 장비에서 정의된것 처럼) 이들이 일반적이다, 라는 것입니다. 당신은 어떤 연산들인지 고려할 필요가 없는데, 왜냐하면 하나의 머신에서 동작하는 것과 완전히 똑같이 실행될 것이기 때문입니다. 이것은 당신이 어떤 연산들이든 간에 같은 시스템을 사용할 수 있다는 것을 알고있기때문에 훌륭합니다.
Total and partial order
분산시스템의 자연적인 상태는 parital order 입니다. 네트워크나 독립적인 노드들 모두 상대적인 순서만을 보장합니다; 그러나 각각의 노드에서는 지역적인 순서를. 관찰할 수 있습니다.
완전한 순서는 이진 관계(binary relation)인데, 집합의 모든 요소의 순서를 정의합니다.
두개의 구분된 요소는 그 중의 하나가 다른 것보다 더 클 경우에 비교가 가능합니다. 부분적으로 정렬된 집합은, 요소들의 어떤 쌍이 비교가능하지 않은데, 부분적인 순서는 모든 항목들에 대해 정확한 순서를 지정하지 않기 때문입니다.
저체 순서와 일부 순서는 전이관계(transitive) 이고 비대칭입니다. 아래의 문구는 전체 순서와 부분순서를 모든 X 의 모든 a,b,c 에 대해 유효합니다.
If a <= b and b <= a then a = b (antisymmetry);
If a <= b and b <= c then a <= c (transitivy);
그러나, 전체 순서는 “전체“입니다:
a <= b or b <= a (totality) for all a, b in X
부분순서는 오직 반사적인 반면에요:
a <= a (refelxitvity) for all a in X
전체성은 반사성을 내포하고 있음을 참고해주세요; 따라서, 부분순서는 전체 순서의 더 약한 변종입니다. 모든 부분순서의 어떤 요소들은, 전체정은 보존되지 않을 수 있습니다 - 다시말해, 어떤 요소들은 비교가 불가합니다.
git 브랜치가 부분순서의 하나의 예입니다. 당신은 알고 있을지도 모르겠는데, 깃 리비젼은 하나의 기본 브랜치에서 여러 복수 브랜치를 생성할 수 있도록 해줍니다 - 예를 들어, 마스터 브랜치에서요. 각각의 브랜치는 공통의 조상으로부터 기반해서 바생된 소스코드의 변화들의 역사를 나타내게 됩니다.
[ branch A (1,2,0)] [ master (3,0,0) ] [ branch B (1,0,2) ]
[ branch A (1,1,0)] [ master (2,0,0) ] [ branch B (1,0,1) ]
\ [ master (1,0,0) ] /
A 와 B 브랜치는 하나의 공통브랜치로부터 파생됐는데, 둘 사이에 어떤 결정적인 순서는 없습니다; 그들은 각각의 다른 역사를 가지고 있고, 추가적인 작업없이 (merging) 하나의 선형으로 좁혀 질 수 없습니다. 물론, 당신은 모든 커밋을 어떤 임의의 순서로 (첫번째로 조상을 두고, 연결들을 부숴서 A 를 B 이전에 두거나, B 를 A 이전에 두거나 하는 방식으로요) - 그러나 이것은 존재하지 않는 전체 순서를 강제로 둠으로써 정보를 잃어버릴 수 있습니다.
하나의 노드의 시스템에서, 전체 순서는 필수적으로 등장하게 됩니다: 명령들은 실행되고 메시지들은 처리되는데, 하나의 프로그램에서 관측가능하게 됩니다. 우리는 이것을 전체 순서라고 믿을 수 있게 됩니다 - 이것은 프로그램의 동작을 예측가능하게 만들어 줍니다. 이런 순서는 분산시스템에서도 유지 될 수 있지만, 비용을 요구하게 됩니다; 통신은 비싸고, 시간 동기화는 어렵고 깨지기 쉽습니다.
What is time ?
시간은 순서의 원천입니다. - 연산의 순서를 정의할 수 있게 해줍니다. - 동일하게 해석을 갖고 사람들이 이해할 수 있습니다. (초, 분, 하루 등.)
어떤 감각에서, 시간은 다른 정수 카운터와 유사합니다. 이것은 대부분의 컴퓨터에서 타임 센서(clock)를 할당하고 있기 때문에 중요합니다. 이것은 또 중요한데, 우리는 물리 실세계에서 촛불이나 세슘원자와 같은 완벽하지 않은 카운터로부터 대략적인 것을 어떻게 합성할지에 대해 파악해왔기 때문에 중요합니다. “합성” 함으로써, 우리는 물리적으로 떨어져있는 것끼리 실제적으로 통신하지 않으면서 대략적으로 정수 카운터의 값을 추축할 수 있었죠.
타임스탬프는 우주의 시작으로부터 현재의 순간까지의 세계의 상태를 나타내는 값입니다. - 만약 특정 타임스탬프에서 어떤 일이 일어난다면, 잠재적으로 이전에 일어난 것에 대해 영향을 받았을 수 있습니다. 이 아이디어는 단순히 타임스탬프 이전의 모든것이 관련이 있다고 가정하는 대신에 명시적으로 원인(의존성들)들을 추적하는 캐주얼 클락으로 일반화 될 수 있습니다. 물론 일반적인 가정은 우리는 모든 세계를 걱정하는 것대신 특정 시스템의 상태만 걱정하면 됩니다.
어디에서든 같은 비율로 시간이 흐른다고 가정합시다 - 이것은 대단히 큰 가정인데, 나중에 다시 돌아오겠습니다 - 시간과 타임스탬프들은 몇가지 유용한 해석을 가지고 있는데(프로그램에 있어서) 3가지 해석은 다음과 같습니다:
- 순서
- 기간
- 해석
Order. 제가 시간은 순서의 원천이라고 얘기했을때, 다음을 의미했었습니다:
- 우리는 타임스탬프를 정렬 되지 않은 이벤트를 정렬하기위해 사용할수 있습니다.
- 우리는 타임스탬프를 연산의 특정 순서로 강제하기 위해서, 혹은 메시지의 전달의 순서를 강제하기 위해 사용할 수 있습니다. (예를 들어서, 순서에 다르게 도달하는 연산은 수행을 딜레이하는 형태로요.)
- 우리는 타임스탬플의 값을 어떤 것이 다른 것보다 시간순으로 더 빨리 일어난 것인지 확인하기 위해 사용할 수 있습니다.
interpretation - 시간은 보편적으로 비교가능한 값입니다. 타임스탬프의 절대값은 날짜로 해석될 수 있으며, 이것은 사람에게 유용합니다. 로그파일로부터 시작된 정지 시가능로 부터 얻어진 타임스탬프는, 천재 지변이 있었던 저번 토요일이었다, 라고 이야기 할 수 있습니다.
Duration - 기간은 실세계에서 어떤 관계를 갖는 시간으로 측정될 수 있습니다. 알고리즘은 일반적으로 시계의 절대값이나 날짜의 해석등을 고려하지 않으며, 그렇지만 이들은 어떤 판단을 하기위해 기간을 사용할 수도 있습니다. 특별히, 소요된 시간의 양은 단서를 제공하기도 하는데, 시스템이 파티션 되었거나, 단순히 고 지연의 경험으로 인한 것인지 등에 대한 것이 그렇습니다.
이런 그들의 본성으로, 분산시스템의 컴포넌트 들은 예측가능한 형태로 동작하지 않습니다. 이들은 어떤 순서도 보장하지 않으며, 진행률이나, 지연이없을 수도 있습니다. 각각의 노드들은 지역 순서를 가지고 있습니다. - 실행이 대략 순차적이기 때문에 - 그러나 이 지역 순서들은 각각에 대해서는 독립적입니다.
순서를 추측하거나, 노출하는것은 가능한 실행의 공간을 줄이는 것의 한 방법입니다. 그리고 가능한 발생을 줄이는 방법의 한 방법입니다. 인류는 어떤 것들이 어떤 순서로든 발생할수 있을때 추리하는것에 어려움을 겪어 왔습니다. - 여기엔 그저 너무 많은 순열들을 고려해야합니다.
Does time progress at the same rate everywhere?
우리는 모두 직관적인 시간에 대한개념을 각각의 경험으로 이해하고 있습니다. 불행하게도, 이 직관적인 시간에 대한 개념은 부분순서가 아니라 전체 순서에 대한 상을 그리게끔 합니다. 어떤 것이 동시에 일어나는것보다, 하나다음에 다음것이 일어날 것이라고 상상하게 합니다. 메시지들의 하나의 순서가 다른 순서나 다른 지연을 가지는것 대신 추리하기가쉽습니다.
그러나, 분산시스템을 구현할때 우리는 시간과 순서에 대한 강한 가정을 갖는것을 피해야합니다. 왜냐하면, 이 강한 가정은, 시간이 맞물린 이슈나, 온보드 클럭 이슈가 발생했을때 깨지기가 쉽기 때문입니다. - 게다가, 순서를 노출하는것은 비용을 요구합니다. 보다 적게 결정적이면 우리는 더 tolerate 해지며, 분산시스템의 이점을 더 활용할 수 있게됩니다.
“시간이 지나는 정도는 어떤 곳이든 같을까? 라는 질문에 대한 세가지 흔한 대답이 있습니다. 그것들은:
- 글로벌 클락: yes
- 지역 클락: no, but
- No clock: no!
세가지 타이밍 추측이 이전 두번째 챕처에서 언급ㅂ한 내용과 어느정도는 일치함을 나타냅니다: 동기화된 시스템 모델은 글로벌 클락을 가지고 있으며, 지역클락을 가지고 있으면 부분적으로 동기화 되며, 비동기화된 시스템 모델은 클락자체를 가지고 있지 않다. 이제 이것들에 대해 좀 더 살펴 봅시다.
Time with a “global-clock” assumption
글로벌 클락의 전제는, 글로벌 클락은 완전히 정밀 하다는 것이며, 모두 여기에 접근가능하다는 것입니다. 이게 우리가 시간에 대해 일반적으로 생각하는 것이며, 시간에 조금 차이가 있어도 사람들사이에 교류는 큰문제가 없기 때문입니다.
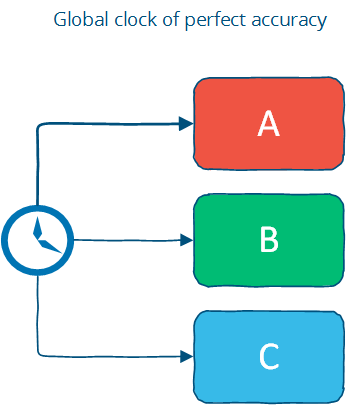
글로벌 클락은 기본적으로 모든 순서의 원천이 됩니다. (정확히 모든 연산들이 모든 노드에서 같은 순서로 실행되고, 서로 통신하지 않더라도.)
그러나, 이것은 세상을 이상적으로 보는 것입니다: 실 세상에서는, 클락을 동기화하는 것은 제한된 정밀도 안에서만 가능합니다. 이것은 클락이 상용화된 컴퓨터 에서는 완전한 정밀도를 갖기가 어려움을 의미하는데, NTP 와 같은 클락 동기화 프로토콜을 사용하는 경우 지연이 발생되고, 근본적으로 우주 시간의 본성(the nature of spacetime) 때문입니다.
분산된 노드들 사이에 완전하게 동기화된 클락이 있다고 가정하는것은 클락이 같은 시간에 시작해서, 절대 표류하지 않아야 함을 의미합니다. 이것은 좋은 가정인데, 당신은 타임스탬프를 사용해서 전체적인 완전 순서를 결정하는데 자유롭기 때문입니다. - 지연이 아니라, clock drift 에 묶이는것 - 하지만, 이것은 쉽지않은nontrivial 도전과제이며, 잠재적인 문제의 원인이 됩니다. 단순 실패에도 많은 시나리오 들이 있습니다 - 유저가 실수로 기계의 로컬타임을 변경한다거나, 최신이 아닌 머신이 클러스터에 들어오거나, 동기화된 클락이 살짝 다른 비율로 표류하거나, 문제를 추적하기 어려운 다른 다양한 원인들이 있을 수 있습니다.
그럼에도 불구하고, 실 세계에서 이런 가정을 하는 것들이 있습니다. 페이스북의 Cassandra는 클락들이 동기화되는 시스템의 하나의 예입니다. 이것은 쓰기들 사이에서 충돌이 일어날때 이를 해결하기 위해 타임스탬프를 활용합니다 - 더 최신의 타임스탬프를 사용하는 쓰기 연산이 승리합니다. 이것은 클락이 표류하면, 새 데이터는 무시되고 이전값으로 쓰여지는 결과를 초래할 수 있음을 의미합니다.; 여기서 다시말하자면, 이것은 운영상의 어려운 문제입니다. 그리고 예전에 들은 바에 의하면, 사람들이 이를 잘 알고 있다고 합니다). 다른 흥미로운 예는 구글의 Spanner 입니다: 이 문서에서는 그들의 시간을 동기화하는 TrueTime API 를 소개하며, 최악의 케이스에 시간이 표류하는 정도를 측정하였습니다.
Time with a “Local-clock” assumption
두번째로, 그리고 또한 더 설득력 있는 가정은 각각의 머신들이 로컬 클락을 가지고 있고, 글로벌 클락이 없는 경우입니다. 이것은 로컬 클럭을 원격 타임스탬프가 로컬 타임스탬프의 이전인지, 후인지 순서를 결정하는데 사용할 수 없음을 의미합니다.; 다시 말해, 두 머신사이에서 타임스탬프를 비교하는데 의미있게 사용할 수 없다는 것을 의미합니다.
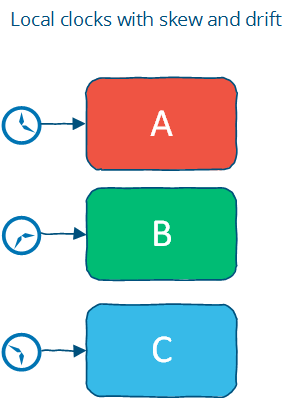
로컬클락추정은 실세계와 좀 더 가깝습니다. 이것은 부분 순서를 갖게 됩니다; 각각의 시스템에서 발생한 이벤트들은 정렬되지만, 시스템들 사이에서 발생한이벤트들은 클락만 사용해서는 순서를 보장할 수 없습니다.
하지만, 당신은 타임스탬프를 하나의 머신에서 발생한 이벤트를 정렬하는 데 사용할 수 있습니다; 그리고 당신은 클락이 어느정도 점프할 수 있다는 것을 허용하고 신중하게 하나의 머신에서 타임아웃을 걸 수도 있습니다. 물론, 엔드유저에 의해 제어되는 머신에 있어서 이것은 너무 많은것을 가정하는 것일 수 있습니다: 예를 들어서, 하나의 사용자가 운영체제의 날짜 컨트롤을 사용하여 실수로 그들의 날짜를 다른 값으로 변경할 수 있기 때문입니다.
Time with a “No-clock” assumption
마지막으로, 논리적인 개념이 있습니다. 우리는 클락을 전혀 사용하지 않고, 대신에 인과관계를 추적하기 위해 어떤 다른 방법을 사용합니다. 기억하세요, 타임스탬프는 단순히 세계를 그 지점에서 상태를 표현하는 표기(shorthand)일 뿐입니다. - 따라서, 우리는 카운터와 통신을 사용하여 어떤 것이 이전에 발생하였거나, 후에, 혹은 동시에 발생하였음을 결정할 수 있습니다.
이 방법은, 우리가 다른 머신들 사이에 발생한 이벤트의 순서를 정할수 있지만, 간격에 대해서 이야기할 수 없고, 타임아웃도 사용할수 없음(타임 센서가 없다고 가정했으므로)습니다. 부분순서를 가지고: 하나의 시스템에서 카운터를 이용하여 통신없이 이벤트를 정렬할 수 있지만, 시스템사이에서 이벤트를 정렬하는 것은 메시지 교환을 요구하게 됩니다.
분산시스템에 대한 글들에서 가장 많이 인용되는 글중에 하나는 Lamport 의 time, clocks and the ordering of events 라는 paper 입니다. 벡터 클락, 개념의 세대(다음에 좀 더 다루겠습니다)는 클락을 사용하지 않고 인과관계를 추적하는 방법중에 하나입니다. 카산드라의 사촌 Riak (Basho) 와 Voldemort (Linkedin) 은 벡터클락을 완벽한 정밀도를 가진 글로벌클락에 접근하는 노드들을 가정하는 대신 벡터클락을 사용합니다. 이것은 이 시스템들이 이전에 이야기한 클락정밀도 이슈들을 회피할 수 있음을 의미합니다.
클락이 사용되지 않을때, 이벤트들이 거리가있는 머신들 사이에서 정렬이 되어야할 때 최대의 정밀도는 통신 지연에 의존하게 됩니다.
How is time used in a distributed system?
시간의 이점은 무엇일까요?
- 시간은 시스템 사이에서 순서를 정의 할 수 있습니다 (통신 없이)
- 시간은 알고리즘의 경계 조건을 정의 할 수 있습니다.
이벤트의 순서는 분산시스템에서 중요한데, 분산 시스템의 많은 속성들이 연산/이벤트들의 순서의 영역에서 정의 되기 때문입니다. :
- 정상 동작(correctness) 이 올바른 이벤트 순서에 의존하는 영역. 예를 들면, 분산 데이터베이스에서의 직렬성.
- 순서는 연결을 끊어 내는 데 사용될 수 있습니다. 리소스 쟁탈(contention)이 일어 났을때, 예를 들어서 만약 위젯을 위한 두 개의 순서(명령)이 있다면, 먼저것을 충족시키고, 두번째 것을 취소 시킬수 있다.
어떤 글로벌 클럭은 연산들이 두 개의 다른 머신들이 직접적으로 통신하지 않고도 정렬할 수 있도록 합니다. 글로벌 클락이 없다면, 순서를 정리하기 위해 통신이 필요합니다.
시간은 또 알고리즘에 대한 경계 조건을 정의하는 데 활용 될 수 있습니다. - 더 정확하게는, 구분하기 위해 “고 지연” 과 “서버나 네트워크 연결이 끊겼다” 이것은 매우 중요한 사용예입니다.; 대부분의 실세계는 타임아웃을 가지고 있고 원격지의 장비가 실패했는지 판단을 위해 타임아웃을 가지고 있거나, 단순히 네트워크 지연이 길어지고 있는 것인지 판단하기 위해 타임아웃을 가지고 있습니다. 이런 결정을 하는 알고리즘은 실패 판단자(failure detectors)라고 불립니다.; 그리고 이것에 대해서는 곧 다시 다루도록 하겠습니다.
Vector clocks (time for casual order)
이전에, 분산시스템에서 시간이 진행되는 비율에 대해 다른 가정이 있음을 언급한적이 있습니다. 동기화된 정확한 클락을 얻을 수 없음을 가정하거나 우리의 목표를 시스템이 시간동기화에 예민하지 않아야 하는 우리의 시스템의 목표를 달성하기 위해, 어떻게 정렬할 수 있을까요 ?
램포트의 클락과 벡터 클락은 카운터와 통신에 의존하는 물리적인 클락 대신 분산시스템의 이벤트들을 정렬합니다. 이 클락들은 다른 노드들 사이에서 비교가능한 카운터를 제공합니다.
A Lamport Clock 은 단순합니다. 각각의 프로세스들은 아래의 규칙에 따라 카운터를 유지합니다.
- 프로세스가 동작하는 언제든지, 카운터를 증가시킨다.
- 프로세스가 메시지를 전송하는 언제 든지, 카운터를 포함한다.
- 메시지가 도달했을때 , 카운터를 max(local_counter, received_count) + 1 로 설정한다.
코드로 표현하면:
function LamportClock() {
this.value = 1;
}
LamportClock.prototype.get = function () {
return this.value;
};
LamportClock.prototype.increment = function () {
this.value++;
};
LamportClock.prototype.merge = function (other) {
this.value = Math.max(this.value, other.value) + 1;
};
어떤 Lamport Clock 은 카운터가 다음과 같은 경고(caveat)와 함께 시스템안에서 비교될 수 있도록 합니다.: 램포트 클락은 부분 순서를 제공합니다. if timestamp(a) < timestamp(b):
a는b보다 먼저 발생했을 수 있거나a는b와 비교될 수 없다.
이것은 클락 일관성 조건이라는 것으로 알려져 있습니다: 만약 하나의 이벤트가 다른것보다 이전에 온다면, 그 이벤트들의 논리적인 클락은 다른것에 비해 이전의 것이라는 것입니다. 만약 a 와 b 가 같은 인과 이력으로부터 파생되었다면, 예를들어, 둘다 같은 프로세스에 의해 생성된 타임스탬프 값을 가지고 있거나; 혹은, b가 a 에서 전송된 메시지에 대한 응답인 경우, a 가 b 보다 먼저 일어 났음을 알 수 있습니다.
직관적으로, 이것은 램포트 클락이 하나의 타임라인에서의 정보를 나르기 때문입니다; 따라서, 램포트 타임스탬프를 서로 통신하지 않는 시스템에서 비교하는것은 실제로 정렬되어있지 않지만 그렇게 보이게하는 동시성 이벤트이슈를 유발할 수 있습니다.
최초의 기간이 지난 후 분리가 되어 서로 통신하지 않는 부분시스템으로 구성되어버린 시스템을 생각해봅시다.
각각의 독립적인 시스템에서 모든 이벤트들에 대해 b 이전에 a 가 일어났다면, ts(a) < ts(b) 라고 할 수 있습니다; 그러나, 만약 당신이 두개의 이벤트를 두 독립적인 시스템으로 부터 가져온다면, (두 메시지는 직접적인 연관이 없다고 합시다.) 여기서 상대적인 순서에 대해 어떠한 의미있는 추론도 할 수가 없게 됩니다. 시스템의 각각의 부분들이 이벤트들에 대해 타임스탬프를 부여한다면, 이 타임스탬프 들은 서로 어떤 관계도 없게 됩니다. 두 이벤트는 관계가 없더라도 순서를 가진 것처럼 보이게 될 수 있습니다.
그러나 - 그리고 여전히 유용한 재산으로 - 싱글 머신의 관점에서, 어떤 메시지가 ts(a) 와 함께 전송되면, ts(b) 값과 함께 응답을 받게 되고, 이것은 > ts(a) 를 만족합니다.
A vector clock 은 [ t1, t2, .... ] N 의 논리적 클락을 유지하는 램포트 클락의 확장판입니다. - 각각의 노드당 하나- 공통적인 카운터를 증가시키는 것 대신에, 각각의 노드들은 자신의 논리적 클락을 벡터안에서 증가시킵니다. (각각의 내부 이벤트에 따라 하나씩). 따라서, 갱신 룰은 다음과 같습니다:
- 프로세스가 동작하는한, 노드의 논리적인 클럭을 벡터안에서 증가시킨다.
- 프로세스가 메시지를 전송할때마다, 논리클락의 모든 벡터를 포함한다.
- 메시지가 수신되면:
- 벡터 안의 각각의 요소들을 다음값이 되도록 갱신한다.
max(local, received) - 벡터에서 현재 노드를 나타내는 논리 클락을 증가시킨다.
- 벡터 안의 각각의 요소들을 다음값이 되도록 갱신한다.
이걸 다시 코드로 표현하면 다음과 같습니다.
function VectorClock(value) {
// expressed as a hash keyed by node id: e.g. { node1: 1, node2: 3 }
this.value = value || {};
}
VectorClock.prototype.get = function () {
return this.value;
};
VectorClock.prototype.increment = function (nodeId) {
if (typeof this.value[nodeId] == "undefined") {
this.value[nodeId] = 1;
} else {
this.value[nodeId]++;
}
};
VectorClock.prototype.merge = function (other) {
var result = {},
last,
a = this.value,
b = other.value;
// This filters out duplicate keys in the hash
Object.keys(a)
.concat(b)
.sort()
.filter(function (key) {
var isDuplicate = key == last;
last = key;
return !isDuplicate;
})
.forEach(function (key) {
result[key] = Math.max(a[key] || 0, b[key] || 0);
});
this.value = result;
};
아래 설명(source) 은 벡터클락을 나타냅니다.
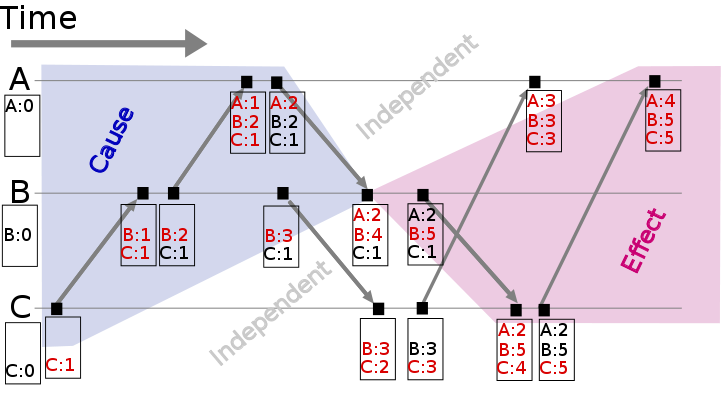
세 노드(A,B, C)의 각각은 벡터 클락을 추적합니다. 이벤트가 발생할때마다, 그들은 벡터 클락의 현재 값들을 타임스탬핑 합니다. 벡터클락을 조사하는것 (와 같은 { A: 2, B: 4, C: 1}) 은 이 이벤트에 잠재적으로 영향받을 수 있는 메시지들을 특정할 수 있게 해줍니다.
이 벡터 클락에 대한 이슈는 주로 노드 별로 하나의 엔트리를 요구한다는 점인데, 이것은 잠재적으로 큰 시스템에서는 큰 비용이 될 수 있습니다. 테크닉의 다양성을 유지하는것은 벡터클럭의 사이즈를 줄이기 위해 적용 될 수 있습니다. (주기적인 가비지 콜렉션을 사용한다거나, 사이즈를 제한함으로써 정밀도를 줄인다거나)
우리는 순서와 인과성을 어떻게 물리적인 클락없이 추적할 수 있을지 살펴봤습니다. 이제, 어떻게 타임 기간이 컷오프를 위해 어떻게 사용될 수 있을지 살펴봅시다.