2. Up and down the level of abstraction
이 챕터에서는, 추상화의 레벨을 여행할 것이며, 몇가지 불가능한 결과를 보고, (CAP 와 FLP), 그리고 나서 성능에 대한 항해를 할 것 입니다.
만약 어떤 프로그래밍을 완료했다면, 추상화. 수준에 대한 개념은 당신에게 익숙할 겁니다. 당신은 이미 추상화와 함께 했고, 어떤 API 를 통해 더 낮은 레이어와 인터페이싱하고 있을 것이며, 더 높은 레이어에 API 나 인터페이스를 제공하고있을 겁니다. OSI 네트워크 7 계층이 좋은 예죠.
분산 프로그래밍은, 단언하고 싶은데, 분산의 결과를 다루는 것이 많은 부분을 차지합니다. 이것은, 현실과 긴장이 있는데, 많은 도들들과 우리의 욕구, 시스템에 대한것은 “하나의 시스템처럼” 이기 때문입니다. 이것은 가능한것과 이해 가능한 것과 성능 사이에서 균형을 잡고 좋은 추상화를 하는 것을 찾아 가는것을 의미합니다.
X 가 Y 보다 더 추상화가 되어있다는 것의 의미는 무엇일까요? 첫째로, X 는 Y 와 근본적인 차이는 없고, 다른 새로운것을 소개 하는 게 아닙니다. 대신, X 는 Y 의 내용을 제거하고 제시하는것, 더 관리하기 쉬운 형태로 제시하는 것을 의미합니다. 둘째로, X 는 Y 로부터 중요하지 않은 문제들을 제거함으로써, 어떤 감각에 대해 Y 보다 더 직관 적일 수 있습니다.
Nietzsche 는 다음과 같이 이야기 했습니다.
모든 동등에 대한것으로 부터 나온 개념은 동등하지 않다. 어떤 이파리(leaf) 도 다른 것과 완전이 같지 않으며, 이파리(leaf) 의 개념은 각각의 차이들로부터 차이에 대한 것들을 잊음으로써 임의의 추상화를 통해 형성된것이다; 또한, 이것은 어떤 아이디어를 도출하는데, 이파리들의 본성은 이파리와 다른 어떤것을 가지고 있을 수 있다는 것이다 - 어떤 종류 모든 이파리로부터 다른 어떤 자기만의 형태가 있을 수 있으며, 낡고, 마킹되고, 복제되며, 색이 다르며, 구부러지고, 색이 다를 수 있지만, 기술적이지 않은 손길로 인해, 맞는것으로, 믿을 수 있고, 신뢰할 수 있는 본래의 형태의 이미지가 되는 복제가 없다. (TODO refined)
추상화는, 근본적으로, 진짜가 아닙니다. 모든 상황들은 유일하며, 모든 노드 또한 그렇습니다. 하지만 추상화는 세상을 관리할 수 있게 해줍니다: 문제 상황들에 대해 더 간단하게 하여 - 현실의 자유 - 더 분석적으로 다룰수있고, 어떤 중요한 것들을 무시하지도 않으면서, 해결책을 넓게 적용할 수 있도록 해줍니다.
실제로, 우리가 다루는 것들은 필수적이면, 우리가 도출할 수 있는 결과도 넓게 적용 가능합니다. 이것은 왜 불가능한 결과가 그렇게 중한지 알려줍니다; 이것들은 문제의 가능한 공식의 가장 단순한 방법을 취하며, 제약과 가정의 집합내에서 해결할 수 없는 문제임을 우리게 설명해 줍니다.
모든 추상화는 의도적으로 유일한 것들을 무시합니다. 이 트릭은 중요하지 않는 것들을 제거하는 것인데, 어떻게 어떤것이 필수적인지 알 수 있을까요? 글쎄, 당신은 아마도 선험적으로(priori) 알지 못할 것입니다.
매 시간 우리는 시스템의 측변에서 제외합니다, 시스템의 특정부분들으세ㅓ. 우리는 에러의 source 로부터 소개하는 리스크를 안고 있습니다. 이것은 왜 때때로 우리가 다른 방향으로 접근해야하는지, 선택적으로 실 하드웨어의 어떤 측변을 선택하고, 실제세계의 문제를 다시 선택적해야하는지. 이 것들은 어떤 하드웨어의 특정 부분들을 (e.g. 물리적인 연속성) 나, 다른 물리적인 특징들이 시스템이 충분히 잘 돌아가도록 충분하다 다시 소개하는 것이.
이것을 머리속에 생각하면서, 분산시스템에서 동작하고 있다는 것을 인지하면서 최소한의 현실은 어떤 것일까? 하나의 시스템 모델은 우리가 중요하다고 고려하는 특징들입니다; 지정한 것들을 갖고 있으면, 불가능한 결과와 도전들을 살펴볼수 있게 됩니다.
A System model
분산시스템에서 주요한 속성중의 하나는, ‘분산’입니다. 더 정확하게는, 분산시스템에서의 프로그램은:
- 각각의 독립적인 노드에서 동시에 실행 됩니다.
- 네트워크를 토앻 연결되어있고, 메시지가 유실되거나 비정의된 동작으로 이어질 수 있습니다.
- 공유 메모리나, 공유 시간이 없습니다. (shared memory, shared clock)
여기에는 많은 암시사항들이 있는데요:
- 각각의 노드 들은 프로그램을 동시에 실행한다.
- 지식들은 지역적이다: 노드들은 그들의 로컬 상태에는 빠르게 접근 하지만, 글로벌 상태에 대한 정보는 잠재적으로 최신 값이 아닐 수 있다.
- 노드들은 실패할수 있으며, 실패로 부터 독립적으로 복구 될 수 있습니다.
- 메시지들은 지연되거나 유실될 수 있습니다. (노드의 실패와는 독립적으로; 네트워크의 실패와 노드 실패 두개를 구분하는 것은 쉬운 일이 아닙니다.)
- clock 들은 접근하는 노드들 사이에서 동기화 되어있지 않습니다. (한 로컬의 타임스탬프는 실제 글로벌 타임과 다를 수 있고, 쉽게 파악하기 어렵습니다.)
하나의 시스템 모델은 어떤 특정 시스템 디자인과 관계하여 많은 가정들을 내포합니다.
System model 분산시스템이 구현된 환경과 시설에 대한 가정들의 집합
시스템 모델들은 그들의 가정, 환경과 시설들에 대한 그들의 가정이 다양합니다. 이 가정은 다음을 포함합니다.
- 노드가 어떤 수용량(capabilities)을 가지고 있고 어떻게 실패할 수 있는지
- 어떻게 통신을 연결하여 동작하고, 어떻게 실패 할 수 있는지
- 전체 시스템의 속성 - 시간과 순서에 대한 가정같은 것들-
건장한 시스템 모델은 가장 작은 가정을 하는 모델입니다; 어떤 알고리즘이 이런 시스템에 쓰여도, 다른 환경에서도 tolerant 하고, 이는 상당히 작은 가정이 있거나, 거의 없기때문입니다.
한편으로, 우리는 시스템모델에 많은 가정을 함으로써 시스템을 이해하기 쉽게 만들수 있습니다. 예를 들어서, 알고리즘에 대해 노드들은 실패하지 않는다. 라는것은 노드의 실패를 다룰 필요가 없게 되죠. 하지만, 이런 시스템 모델은 현실적이지 않으므로 적용 할 수가 없죠.
노드의 속성들을 살펴보고, 시간과 순서에 대해 좀 더 살펴봅시다.
Nodes in our System model
노드들은 연산과 저장소의 호스트로서 동작하게 되는데, 이들은 다음을 갖고 있습니다:
- 프로그램을 실행할 수 있는 능력
- 데이터를 휘발성 메보리에 저장할 수 있는 능력과 (실패시에는 소실될 수 있는) 안정적인 상태로 저장 할 수 있는 능력 (실패 이후에도 읽을 수 있는)
- a clock (정확하다고 믿거나 믿지 않을 수 있는 시계)
노드들은 결정적인(deterministic) 알고리즘들을 실행합니다; 내부 연산, 연산 이후의 내부 상태, 메시지를 수신한 이후 자체적으로(uniquely) 결정한 메시지를 전송한다거나.
노드가 실패 했을 때의 동작을 기술한 많은 실패 모델들이 있는데, 실제로는 (in practice), 대부분의 시스템들이 크래쉬-복구 실패 모델을 가정합니다; 이것은, 노드들이 크래쉬가 났을 경우에만 실패하며, 일정 시점 이후에는 복구 할 수 있다 라고 가정합니다.
다른 대안은 노드는 임의의 다른 의도하지 않은 동작을 하여 실패할 수 있다고 가정하는 것인데요, 이것은 비잔틴 실패 tolerance 라고 알려져 있습니다. 비잔틴 실패는 상용 시스템에서는 거의 다뤄지지 않으며, 임의의 실패에 대응 할 수 있는 알고리즘은 구현하기가 훨씬 복잡하고, 비싸기 때문입니다. 이것에 대해 다루지는 않겠습니다.
Communication links in our system model
통신 연결들이 각각의 도드들을 연결하며, 메시지들이 어떤 방향으로도 전송 될 수 있도록 해줍니다. 많은 책들에서 분산 알고리즘들은 각각의 노드 쌍에 대해 각각의 연결, 메시지에 대해 FIFO 를 제공하고 그들이 보낸 메시지만 전달하고, 유실될수 있다고 가정합니다.
어떤 알고리즘들은 이 네트워크가 신뢰할 수 있다고 믿습니다; 메시지들은 절데 유실되지 않으며 절대 무기한 연기되지 않는다. 이런 가정들은 어떤 실세계의 설정에서는 유효한 가정이지만, 일반적인 경우에는 네트워크는 신뢰할 수 없으며 대상들은 메시지를 유실하거나 지연할 수 있다고 고려하는것이 선호 됩니다.
네트워크 파티션은 네트워크가 실패하여 다른 노드들 자체들은 연산가능한 상태로 남아 있을 때 발 생합니다. 이것이 일어나게 되면, 메시지들은 유실되거나 네트워크 파티션이 복구 될때까지 지연되게 됩니다. 파티션 된 노드들은 어떤 클라이언트에게는 정상적으로 접근가능하므로, 크래쉬 노드와는 다르게 처리되어야 합니다. 아래의 다이어그램은 노느 실패와 네트워크 파티션을 나타냅니다.:

통신링크에 대해 더 많은 가정을 하는 것은 드뭅니다. 우리는 연결들이 하나의 방향성만 가진다고 가정하거나, 다른 커뮤니케이션 비용을 소개할 수 도 있습니다. (e.g. 물리적 거리로 인한 지연) . 그러나, 이것들은 상업적 환경에서는 큰 걱정사항이 아니며 (WAN 지연과 같은 긴거리의 연결을 제외하고) 그렇기때문에 여기서 논의 하지 않겠습니다; 더 자세한 비용과 topology 에 대한 모델은 복잡성에 대해 더 나은 최적화를 하게 됩니다.
Timing / ordering assumtions
각각의 노드들이 물리적인 분리가 되어있다는 것은 세상을 유일한 매너로 볼 수 있게 해 줍니다. 이것은 피할 수 없는데, 광속을 뛰어넘는 정보란 있을 수 없기때문입니다. 만약 노드들이 각각 다른 거리에 있고, 어떤 메시지지들도 하나의 노드에서 다른 노드로 전송되면, 노드들 사이에서 각각 다른 순서와 시간으로 도달 할 수 있습니다.
타이밍에 대한 가정은 현실을 고려할 때 확장하기에 쉽게 해 줍니다. 주요한 두 대안들은:
Sychronous system model 프로세스들은 락 단계 에서 실행됩니다; 메시지 전송 지연에는 알려진 상한이 있으며; 각각의 프로세스들은 정확한 clock 을 가지고 있습니다.
Asynchronous system model 타이밍에 대한 가정은 없습니다 -e.g. 프로세스들은 독립적인 비율로 실행합니다; 메시지 전송 지연에 대한 범위는 없으며; 유용한 clocks 도 없습니다.
동기화된 시스템 모델은 시간과 순서에 대한 많은 제약들을 두고 있습니다. 이것은 필수적으로 노드들이 같은 경험을 하도록 가정합니다; 메시지들은 항상 최대 전송 지연 시간 안에 수신되어야하며, 락 단계( lock-step) 에서 실행 되어야 합니다. 이것은 시스템의 디자이너가 시간과 순서에 대한 많은 가정을 할 수 있게 하므로, 편리한 반면에, 비동기화된 시스템모델은 그렇지 않습니다.
비동시성은 가정이란 없습니다; 그저 타이밍에 대한 가정을 할수 없다 라는 가정 만이 있습니다.
동기화된 시스템 모델에서 문제를 푸는 것이 더 쉬운데, 실행 스피드, 최대 메시지 전송지연, 시계 정확성에 대한 가정 모두 문제를 푸는데 도움을 주기 때문인데, 이는 가정에 기반하여 추론을 할 수 있게 해주고, 일어나지 않을 것이라고 가정하는 불편한 실패 시나리오들을 생각할 필요가 없기 때문입니다.
물론, 동기화된 시스템 모델을 고려하는것은 일부는 현실적이지 않스빈다. 실세계의 네트워크는 실패할 수 있으며, 메시지 딜레이에 대한 강력한 범위도 없스빈다. 실세계의 시스템은 최대한 일부적으로 동기화 되어있습니다: 때때로 올바르게 동작하고 최대 지연 범위를 제공하지만, 메시지가 무한하게 딜레이될 수 있고 시계들은 동작에서 벗어 날 수 있습니다. 여기서 동기화된 시스템의 알고리즘에 대해 다루진 않을 것이며, 분석하기 쉽기 때문에 (현실적이지 않지만) 다른 책들에서 많이 다루고 있을 겁니다.
The consensus problem
이 문서의 나머지에서, 우리는 시스템모델의 인자들을 다양화 할 것 입니다. 이후에는, 어떻게 두 시스템 송성들을 다양화 할 것인가에 대한 것을 살펴 봅니다.
- 네트워크 파티션이 실패 모델에 포함을 할 것인지,
- 동시성 vs. 비 동시성의 타이밍 가정을 할 것인지.
시스템 디자인 선택의 영향은 두 불가능한 결과(FLP 와 CAP) 를 논의 하는것에 의해 영향을 받습니다.
물론, 논의를 하기 위해, 풀어야할 문제를 소개할 필요가 있겠네요. 바로 타협 문제입니다.
몇몇 컴퓨터 (노드) 들은 그들이 어떤 값들에 대해 모두 동의 할 수 있습니다. 더 격의 적으로 이야기하면:
- 동의: 모든 올바른 프로세스들은 같은 값들에 동의 해야합니다.
- 통합: 모든 올바른 프로세스들은 최대 하나의 값을 결정하고, 어떤 값을 정하면, 어떤 프로세스에 의해 제안 되어야 합니다.
- 종료: 모든 프로세스들은 결과적으로 결정에 다달아야 합니다.
- 유효성: 만약 모든 올바른 프로세스들이 같은 값 V 를 제안했다면, 모든 올바른 프로세스들이 V 를 결정한 것입니다.
이 타협 문제는 많은 상업용 분산 시스템에서의 주요 문제 입니다. 결과적으로, 우리는 분산에서의 부작용을 다루지 않고 신뢰성과 성능을 얻고 싶으며, aotmic broadcase 와 atomic commit 같은 타협문제와 관련한 더 발전된 문제들을 풀고 싶어하죠.
Two impossibility results
첫번째 불가능한 결과 (FLP imossibility result 로 알려진)는 분산시스템을 설계한 사람에 관계한 불가능한 결과 입니다. 두번째는 - The CAP 이론- 실무자에 더 관계한 결과 입니다; 시스템 디자인을 선택 하는 사람들이 알고리즘 디자인에 대한 직접적인 고려가 없는 경우에 해당합니다.
The FLP impossibility result
간략하게 FLP 불가능 결과 에 대해 요약해 보면, (교육계에서는 더 중요하게 고려 되지만) FLP 불가능 결과 (Fishcher, Lynch and Patterson 저자에 의해 지어진 이름입니다.) 비동기 시스템 위에서 타협 문제를(기술적으로, 타협문제의 작은 형태인 동의 문제) 검사합니다. 노드들은 크래쉬에 의해 실패할 수 있다고 가정합니다.; 네트워크는 신뢰할 수 있고, 비동기 모델에서의 일반적인 타이밍 문제는 유지 됩니다: e.g. 메시지 지연에 대한 범위는 없습니다.
이런 가정하에, FLP 결과는 “(deterministic)한 알고리즘은 실패할 수 있는 비동기 모델에서 메시지가 절대 유실되지 않더라도, 최대 하나의 프로세스만이 실패할 수 있더라도, 그 이유가 오로지 크래쉬에 의한 것이라도 존재할 수 없다.” 라고 이야기 합니다.
이 결과는 무한하게 지연될 수 없다.라고 가정한 최소한의 시스템 모델에서는 타협문제를 풀 방법이 없다고 이야기 합니다. 이 논쟁은 이런 알고리즘이 존재한다면, 메시지 전송이 임의의 시간동안 지연될 수 있는 결정되지 않은 상태로 남아있는 (2가의 -bivalent) 알고리즘을 고안 할 수 있을 것이다. 그러므로, 이런 알고리즘은 존재하지 않는다. 에 대한 것입니다.
이 불가능 결과는 비동기 시스템 모델이 tradeoff 를 가짐에 초점을 맞추고 있기 때문에 중요합니다.: 타협문제를 푸는 알고리즘은 메시지 전송에 관한한 지연 범위를 보장할 수 없을때에는 안정성이나 실시간 성을 포기해야함을 시사하고 있습니다.
이 통찰은 알고리즘을 디자이낳는 사람들에게 더 관계가 있는데, 비동기 시스템 모델에서 풀 수 있다고 알고 있는 문제에 대해 더 강한 제약을 의미하기 때문입니다. CAP 이론은 실무자에게 더 관련되어 있습니다; 이것은 다소 다른 가정(노드 실패가 아닌 네트워크 실패) 만들고, 시스템 디자인 선택을 할때에 실무자가 더 명확한 의미를 갖도록 합니다.
The CAP theorem
CAP 이론은 처음에는 컴퓨터 과학자 Eric Brewer 에 의해 추측되었습니다. 시스템 디자인을 정할 때 tradeoff 에 대해 생각하는 꽤 유용하고 유명한 방법입니다. Gilbert 와 Lynch 의 공적인 증명 도 있으며, Nathan Marz 는 논의 사이트 가 생각하는 것에도 불구하고 폭로하지 않았습니다. (TODO refined. It even has a formal proof by Gilbert and Lynch and no, Nathan Marz didn’t debunk it, in spite of what a particular discussion site thinks.)
이 이론은 다음과 같은 세가지 속성을 가집니다.:
- 일관성: 모든 노드들은 같은 때에 같은 값을 가진다.
- 가용성: 노드 실패가 다른 생존자들이 동작하는 것을 막지 않는다.
- 일부 tolerance: 시스템은 네트워크나 노드 실패로 인한 메시지 유실에도 계속해서 동작한다.
동시에 두개 만이 만족될 수 있습니다. 보기좋게 다이어그램으로 만들어보면, 셋 중에 두 속성을 선택하는 것은 세가지의 시스템 타입을 나타내는데, 각각의 교집합으로 표현 되어 있습니다.
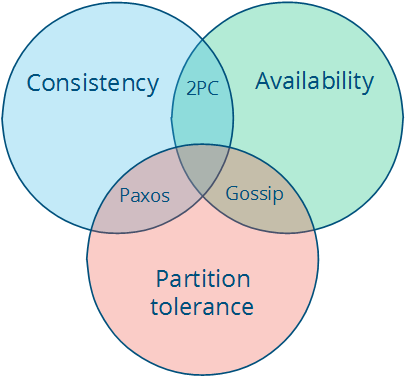
이 이론은 (모든 세개의 속성에서) 중앙의 조각은 얻어질 수 없음을 이야기 합니다. 세개의 시스템 타입은 다음과 같습니다.
- CA (consistency + availability). 정족수(quorum) 규약을 엄격히 따르는 예제로서, 2 phase commit 과 같은 예를 생각해볼 수 있습니다.
- CP (consistency + partition tolerance). 다수 정족수를 따르는 경우로, 소수의 파티션은 (Paxos 같은) 사용할 수 없게 됩니다.
- AP (consistency + partition tolerance). 다이나모 같은 충돌 해결을 사용하는 프로토콜입니다.
CA 와 CP 시스템 디자인은 모두 같은 일관성 모델을 제안합니다: 강력한 일관성. 둘의 유일한 차이는 CA 는 노드 실패에 대해 tolerate 하지 않다는 접입니다; CP 시스템은 비잔틴 실패가 없는 2f + 1 노드에서 f 실패까지 tolerant 합니다. (다시 말해서, 다수인 f + 1 이 살아 있는 동안 소수인 f 의 실패까지는 버틸 수 있습니다.) 그 이유는 간단합니다:
- CA 시스템은 도드의 실패와 네트워크 실패를 구분하지 않으며, 따라서 분리(복수의 복제)를 피하기 위해 쓰기를 중지해야합니다. 이것은 원격의 노드가 내려간 것인지, 네트워크 연결이 중지된 것인지 말할 수 없습니다: 따라서 유일한 안전한 방법은 쓰기를 중지하는 것 뿐입니다.
- CP 시스템은 두 파티션의 비대칭 동작을 강제로 막음으로써 분리(divergence - 한개의 복제 일관성 만을 유지합니다)를 막습니다. 만약 다수의 파티션을 유지하기만 한다면, 소수의 파티션만이 비가용 적이도록 유지한다면, (e.g. 쓰기를 막는다), 가용정도는 유지하면서 여전히 하나의 복제 일관성만을 유지할 수 있습니다.
이 것들에 대해서는 Paxos 에 대에 논의 할때 복제에 대해 더 자세히 다루겠습니다. CP 모델에서 중요한것은 협조적이지 않은 네트워크 파티션은 다수의 파티션과 구분한다는 것입니다. (Paxos, Raft, viewstamped 복제와 같은 알고리즘을 사용하여) CA 시스템은 파티션에 자각적이지 않고, 역사적으로 더 흔한 시스템 입니다; 보통 2-phase 커밋 알고리즘 같은 것들이 전통적인 분산 관계형 데이터 베이스에서 흔히 사용됩니다.
파티션이 일어 났다고 가정했을때, 이 이론은 가용성과 일관성, 어떤 것을 선택할 것인지로 문제를 줄입니다.
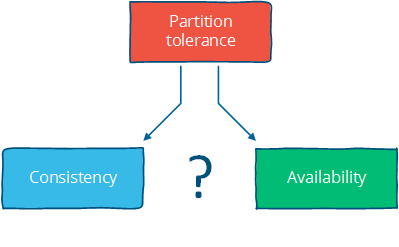
CAP 이론으로부터 4개의 결론을 낼 수 있을 것 같네요.
첫째, 전통적인 관계형 데이터베이스와 같은 분산시스템 디자인들은 파티션 tolerance 에 대해 다루지 않았다. (e.g. CA 디자인이었다). 파티션 tolerance 는 현대의 시스템에서는 중요한 속성이며, 네트워크 파티션이 물리적으로 분산되어 더 잘발생할 수 있어졌기 때문입니다.
둘째, 네트워크 파티션이 발생하였을때 강력한 일관성 모델과 높은 가용 성을 유지하는것 사이에서 긴장이 있다. CAP 이론은 분산 연산에서 강력한 보장을 위해서는 tradeoff 가 있음을 설명하고 있습니다.
어떤 경우에는, 예측할 수 없는 네트워크로 연결되어있는 독립적인 노드들로 이루어진 분산 시스템에서 “비분산 시스템과 구분할수 없는 방식으로 동작하게 할거야” 라는 것을 약속하는 것은 꽤 미친 짓이죠!"

강력한 일관성은 파티션이 발생한 동안은 가용성을 포기합니다. 이것은 두 복제가 서로 통신할 수 없는 상황에서 양쪽 파티션에서 쓰기를 허용하면 분리(divergence)를 막을 수 없기 때문입니다.
어떻게 이것들 사이에서 일할 수 있을까요? 가정을 더 강화(파티션은 없어!) 하거나, 보장을 약화할 수 밖에 없습니다. 일관성은 가용성과 tradeoff 관계에 있습니다.(또, 오프라인 접근성의 용량과 낮은 지연과 관련해 있습니다). 만약 “일관성” 이 “모든 노드들은 동시에 같은 데이터를 보고 있다” 라는 것보다 작은 것이라면, 가용성과 더 (약한) 일관성을 보장 받을 수 있습니다.
셋째, 일반적인 동작에서, 강력한 일관성과 성능 사이에는 긴장이 있다
강력한 일관성 / 하나의 복사 일관성은 노드 통신이 되면서 모든 연산에 대해 동의 해야함을 의미합니다. 이것은 일반적인 연산에 있어서 높은 지연으로 이어집니다.
만약 고전적이지 않은 일관성 모델에서 살고 있다면, 복제의 지연이나 분리를 허용하고 있을것이며, 이후에 일반적인 연산을 하면서 지연을 줄이고 파티션의 존재에 대해 가용성을 유지하고 있을 것입니다.
더 적은 메시지와 더 적은 노드가 관계할수록 어떤 연산들은 더 빠르게 완료될 수 있습니다. 하지만 이것을 이루기 위해서는 보장을 완화하는 방법밖에 없습니다: 어떤 노드들이 더 적게 접촉할수록 할수 밖에 없는데, 이는 이전 데이터를 갖고 있다는 의미죠.
이 것은 이상(anomalies) 가 이뤄지게 합니다. 더이상 최신의 값을 보장 받을 수 없습니다. 어떤 보장을 받을지에 의존 함에 따라서, 당신은 기대보다 이전의 데이터를 읽을 수 있으며, 심지어 수차례의 업데이트를 놓칠 수도 있습니다.
넷째 - 좀 간접적이지만 - 네트워크 파티션으로 인한 가용성을 포기하고 싶지 않다면, 우리의 목적을 위해 강력한 일관성과는 다른 일관성 모델을 찾을 필요가 있다
예를 들어서, 유저 데이터가 물리적으로 여러 데이터 센터에 있더라도, 두 데이터 센터의 연결이 일시적으로 고장나더라도, 대부분의 경우에 유저가 우리의 웹사이트/서비스를 이용하게 허용하고 싶습니다. 이것은 나중에 두 데이터를 다시 화해( reconciling -비지니스 적으로도 리스키하고 기술적으로도 도전적인 작업인 -) 시켜야함을 의미합니다. 그러나, 이 기술적으로 도전적이고 비즈니스적으로도 리스키한 작업이 종종 관리 될 수 있으며, 고 가용성을 위해 선호 되는 편입니다.
일관성과 가용성은 강력한 일관성으로 제약하지 않는다면, 사실 완전히 이지선다는 아닙니다. 강력한 일관성은 그저 하나의 일관성 모델일 뿐입니다: 활성화 되어있는 하나만의 데이터를 유지하기 위해서만 가용성을 포기해야할 필요가 있죠. Bewer 자신이 지적한 것처럼, “셋 중의 둘” 이라는 해석은 잘못된 것이라고 할 수 있습니다.
만약 이 토론에 대해 하나의 아이디어만 뽑아낸다면, 이것일 것입니다. “일관성” 은 단수형이나, 모호하지 않은 속성이 아닙니다. 기억하세요.
ACID 일관성 !=
CAP 일관성 !=
Oatmeal 일관성
대신에, 일관성은 그걸 사용하는 프로그램에 데이터 저장소가 제공하는 보증입니다.
Consistency model 시스템은 프로그래머가 어떤 특정한 규칙에 따른다면 시스템이 데이터가 저장되는 결과가 예측가능하도록 보장하는 프로그래머와 시스템 사이의 계약서
CAP 의 “C” 는 강력한 일관성이 지만, “일관성"은 “강력한 일관성"과 같은 말이 아닙니다.
이제 다른 일관성 모델을 살펴 보죠.
Strong consistency vs. other consistency models
일관성 모델은 두가지 타입으로 분류 될 수 있습니다: 강력하거나, 약하거나:
- 강력한 일관성 모델 (하나의 복사만을 유지함)
- 선형 적인 일관성
- 순차적인 일관성
- 약화된 일관성 모델 (강력하지 않음)
- 클라이언트 사이드의 일관성 모델
- 캐주얼한 일관성: 강력한 모델이 가능할 때
- 결과적으로 일관적인 모델
강력한 일관성 모델은 명확한 순서나, 갱신에 대한 가시성을 보장하여 복제 되지 않은 시스템과 동등한 시스템을 유지합니다. 약화된 일관성 모델은, 반면에, 이런 보장들을 하지 않습니다.
이것이. 철저한 리스트는 아님을 주지해주세요. 다시 말해서, 일관성 모델은 임의의 계약 (시스템과 프로그래머 사이의) 이어서, 어떤 것이든 될 수 있습니다.
Strong consistency models
강력한 일관성 모델은 두 비슷한 모델로 나뉘어 질 수 있습니다. (일부가 다릅니다.)
- 선형적인 일관성: 이 일관성 모델에서는, 모든 연산들이 아토믹하게 순서대로 이뤄지며 글로벌 실세계의 연산 순서를 따릅니다. (Herilhy & Wing, 1991)
- 순차적인 일관성: 이 일관성 모델에서는, 모든 연산들은 모든 노드와 동등한 각각의 노드들에 의해 일관적인 순서로 아토믹하게 연산이 이뤄집니다. (Lamport, 1979)
두 일관성 모델의 차이가 되는 열쇠는, 선형적인 일관성에서는 실시간의 연산 순서와 동등하게 연산이 수행 되어야 한다는 점입니다. 순차적인 일관성은 각각의 노드에서 확인 할 수 있는 일관성이 유지 되는한, 연산이 재배치 되는 것을 허용합니다. 이 둘을 구분할수 있는 유일한 방법은 입력이 시스템에 반영되는 타이밍을 관찰하는 것 밖에 없습니다; 노드들과 교류하는 클라이언트의 관점에서는, 둘은 동등합니다.
두 차이는 중요하지 않은 것 같아 보이지만, 순차적인 일관성이 결합하지 않는 다는 점은 주목할 필요가 있습니다.
강력한 일관성 모델은 프로그래머가 하나의 서버를 분산된 도드들의 클러스터로 대체하여도 어떤 문제도 없게 해 줍니다.
모든 다른 일관성 모델은 anomailies (강력한 일관성 모델과 비교해서)가 있으며, 복제되지 않은 시스템과 구별되는 동작을 하기 때문입니다. 하지만, 이런 이상 증상들은 보통 수용가능하며, 일시적인 이슈는 괜찮거나, 비 일관적인 상태를 다루도록 코드를 작성했기 때문입니다.
약화된 일관성 모델에서 범우주적인 토폴로지는 없다는 것을 명심해주세요. 왜냐하면, “강력한 일관성모델이 아닌 모델” (e.g. 어떤 방식으로든 복제되지 않는 시스템과 구분가능한것”) 은 어떤 모양이든 가질 수 있으니까요.
client-centric consistency models
client-centric consistency models는 클라이언트나 세션의 개념을 포함한 일관성 모델입니다. 예를 들면, 클라이언트 중심 일관성 모델은 클라이언트는 절대 예전버전을 보지 않음을 보장하는 것이죠. 이것은 종종 클라이언트 라이브러리에서의 추가적인 캐싱을 구현하여 클라이언트가 예전 버전의 복제 노드로 이동하면, 예전 데이터를 보유한 복제본의 데이터를 반환하는 것 대신 캐쉬의 데이터를 반환 하는 형태로 구현됩니다.
클라이언트는 예전 버전의 데이터를 볼수 있지만, 복제본의 노드가 최신의 데이터를 갖고 잇지않다면, 그렇지만 이전 버전의 재 표면화로 인한 (e.g. 다른 복제본으로 연결 됨으로 인해) 이상현상은 보지 않게 됩니다. 이런 일관 성 모델에는 많은 종류가 있다는 것을 기억해 주세요.
eventual consistency
결과적 일관성 모델은 값을 변경하는 것을 멈춘다면, 정의되지 않은 얼마간의 시간뒤에 모든 복제들은 같은 값을 갖게 됩니다. 이것은 그 시간 전까지는 복제본들 사이에서 정의되지 않은 형태로 일관적이지 않은 데이터를 가질 수 있음을 내포하고 있습니다. 사소하게 만족적 이기 때문에, 보충 정보가 없이는 유효하지 않습니다.
어떤것을 단순하게 결과적으로 일관적이다. 라고 이야기 할때, “사람들은 결과적으로 죽는다” 라고 이야기하는 것과 비슷합니다. 이것은 상당히 약한 제약조건이며, 최소한 다음과 같은 두 특징을 얻기를 원할 것입니다.:
첫째, “결과적으로” 라는 것은 얼마나 긴 것인지? 이것은 하한선을 정해 두는 것이 유용할 수 있으며, 아니면, 같은 값에 대한 시스템의 커버리지를 일반적으로 얼마나 길것인지 에 대한 최소한의 아이디어를 가져가는 형태입니다.
둘째로, 어떻게 값에 대한 동의를 할 것 인가? 인데, “42” 라고 항상 이야기하는 시스템은 결과적으로 일관적 입니다: 모든 복제본들은 같은 값을 통의합니다. 이것은 단지 유용한 값에 대해 커버리지가 없을 뿐입니다. 대신에, 우리는 방법에 대한 더 좋은 아이디어가 있습니다. 예를 들면, 가장 큰 타임스탬프를 가진 값이 항상 이기는 것입니다.
따라서, 제공자가 “결과적으로 일관적이다” 라고 이야기하면, 더 정확한 용어를 의미하는 것일 수있습니다. “결과적으로 최근값이 이기고, 그동안 가장 최근값으로 관측 되는 값이 일겅진다” 일관성과 같이 요. 이 “어떻게?” 가 관건이며, 좋지 않은 메소드는 쓰기 작업을 잃어버릴 수도 있기 때문입니다. 예를 들어서, 만약 어떤 노드의 시계가. 잘못 설정되어 있었고, 그 타임스탬픅가 사용될 수 도 있죠…
이 두가지 질문에 대해 약화된 일관성 보델에 대한 복제 방식 챕터에서 더 자세히 다루겠습니다.