1. Distributed systems at a highlevel
- 분산 프로그래밍은 같은 문제를 하나의 컴퓨터에서 해결할 수 있는 문제를 여러 컴퓨터에서 해결하는 예술이다.
컴퓨터 시스템이라면 해결해야 하는 두개의 문제가 있습니다.
- 저장소
- 연산
분산 프로그래밍은 하나의 컴퓨터에서 해결할 수 있는 문제를 여러 컴퓨터를 통해 해결하는 예술입니다. 보통 하나의 컴퓨터에서 해결하기에는 적합하지 않은 문제를 위해서입니다.
실세계에서의 어떤것도 분산시스템을 요구하지는 않습니다. 무한한 돈과 무한한 실시간 연구 시간이 있다면, 분산시스템은 필요없습니다. 모든 연산과 모든 저장소는 매직박스 안에서 실행 될 수 있습니다 - 하나의, 믿을 수 없을정도로 빠르고, 믿을 수 없을정도로 신뢰할 수 있는 시스템은 누군가에게 돈을 지불하거나 당신이 직접 디자인할 필요가 있겟죠.
하지만, 그렇게 무한한 자원을 가지고 있는 사람은 별로 없습니다. 때문에, 그들은 좋은 장소와실제 세계에서, 비용적인 측면에서 고려할 수 있는 적합한 실세계의 장소를 찾아야 합니다. 작은 사이즈 에서는 하드웨어를 업그레이드 하는 것은 필수적인 전략입니다. 하지만, 문제의 사이즈가 커짐에 따라 싱글 노드의 하드웨어 업그레이드 만으로는 문제를 해결할수 없거나, 비용적으로 막히는 지점이 오게 됩니다. 이 포인트에서, 분산 시스템으로 오신것을 환영할 때가 된것 같네요!
이것은 현재의 현실이고 어떤 현실이냐면 가장 가치있는 중앙 범위, 상업적인 소프트웨어 - 유지보수 비용이 문제가 발생했을때도 괜찮은 소프트웨어로 유지될 수 있도록 해줍니다.
연산(computations)은 대부분 고수준의 하드웨어가 네트워크 접근을 내부 메모리 접근으로 변경했을때 혜택을 본다고 할 수 있습니다. 노드들 사이에서의 방대한 커뮤니케이션을 요구하는 작업들로 인해 제한 되던 하드웨어들에서 효과를 볼 수 있겠죠.
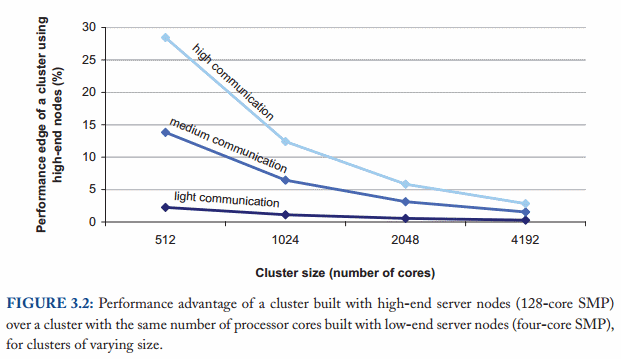
위의 Barroso, Cildaras & Holzle 피규어에서 보여주듯, 고수준과 상품(commodity) 하드웨어의 성능 차이가
모든 노드에 걸쳐 하나의 메모리 접근으로 가게 됨에 따라 줄어듦을 살펴 볼수 있습니다.
이상적으로, 하나의 머신을 추가하는 것은 시스템의 생산력과(capacity) 성능을 선형적으로 올려줄겁니다. 그러나 물론 이것은 불가능하며, 분리된 컴퓨터들 사이에 오버헤드가 추가 됨으로써 야기 됩니다. 데이터들은 복사될 필요가 있고, 연산 작업들은 조정되어야 하는 등의 작업들이 그렇습니다. 이 때문에 분산 알고리즘을 공부하는 것에 가치가 생기게 됩니다. - 어떤 문제들에 있어서 효율적인 솔루션을 제공하고, 가능하다면 올바르게 구현함을 통해 최소한의 비용만 사용할 수 있도록 가이드 해주거나, 불가능함을 알 수 있게 됩니다.
이 문서의 목적은 일반적인 경우의 분산 프로그래밍에 대해 초점을 둘 것 이지만, 상업적에 관련한 설정에 대해서도 관심을 둘겁니다: 데이터 센터. 예를 들어서, 괴짜적인 네트워크 설정에 대해서는 논의 하지 않을것이며, 공유 메모리를 위한 설정에 대해서도 이야기 하지 않을 겁니다. 또한, 이 문서에서는 어떤 특정 디자인에 대해 최적화를 하기보다, 시스템 디자인 공간을 탐험하는데 시간을 할애할 겁니다. - 특정 디자인에 대한 최적화는 보다 특화된 주제 입니다.
What we want to achieve: Scalability and other good things
모든 것은 결국 사이즈를 다루는 데서 시작합니다.
대부분의 것들은 사소하고, 작은 스케일에서 시작되도 됩니다. - 그리고 같은 문제들은 어떤 특정사이즈, 볼륨, 물리적인 제약을 초과하게 되면서 점점 어려워지게 됩니다. 초콜릿을 들어올리는 것은 쉽지만, 산을 들어올리는 것은 어려워 집니다. 한 방에 몇명이 있는지 세는 것은 쉽지만, 한 나라에 얼마나 많은 사람들이 있는지 세는것은 어려워 지듯이요.
그래서, 모든것은 사이즈에서 시작합니다 - 확장성. 공식적으로 말해서, 문제들이 크게 나빠지지 않도록 작은 시스템에서 큰 시스템으로 확장될 수 있는 시스템. 여기 다른 정의가 있습니다.
Scalability: 어떤 시스템, 네트워크, 프로세스의 늘어나는 작업을 핸들링 하거나, 수용력을 확장할 수 있도록 하는 능력.
‘늘어난다’는 것은 무엇인가? ‘성장’을 어떤 용어로는 측정할 수 있습니다. (사람이 늘어난다, 전력량이 늘어난다 등등). 하지만, 다음과 같이 특히 관심게 봐두면 좋을 것들이 있습니다.
- 사이즈의 확장성: 노드를 추가하면, 시스템을 선형적으로 빠르게 만들어야 한다; 데이터집합의 증가가 지연을 만들지 않아야 한다.
- 지역적인 확장성: 복수의 데이터 센터를 사용하여 유저의 쿼리에 대한 응답성을 유지해야하며, 데이터 센터의 교점에 있어서는 감각적인 방법으로 잘 처리해야할 것.
- 운영적인 확장성: 노드를 추가하는것 운영 코스트를 증대 시키지 않아야한다. (운영자-장비 비율)
물론, 실제 시스템의 증대는 다른 차원의(여러 축의) 문제이긴 합니다.; 각각의 메트릭(요소)들이 성장의 한 측면을 캡쳐하고 있습니다.
확장 가능한 시스템은 유저가 증대됨에도 지속적으로 요구를 충족시킴을 의미합니다. 이것에 관련한 두개의 관점이 있습니다. - 성능과 가용성 - 이것들은 다양한 방법으로 측정될 수 있습니다.
Performance (and latency)
Performance 는 시간과 리소스 측면에서 유용한 작업의 양으로 특징할 수 있다.
문맥에 따라, 아래의 내용과 한 개 이상 관여할 수 있습니다.
- 주어진 작업 수행을 위한 응답성/적은 지연
- 높은 처리량 (처리량의 비율)
- 낮은 리소스 사용률
이런 결과를 얻기 위해 포기해야할 비용들이 있기 마련입니다. 연산 오버헤드를 줄이고 높은 처리량을 위해 더 큰 배치를 처리하는경우, 개별의 작업에 대한 응답은 더 늦어지는 결과로 이어지게 되는것처럼요.
낮은 지연 - 빠른 응답성 - 은 성능에 있어서, 물리적(비용적인 측면보다는)인 제약에 크게 영향받기 때문에 가장 관심있는 요소가 됩니다. 성능의 다른 요소들에 비해 비용을 투자해서 ‘지연’을 다루기엔 어렵죠.
지연에 대한 많은 정의가 있지만, 다음과 같이 연상되는 아이디어를 좋아합니다.
Latency 지연된다; 지연, 어떤 것이 개시된 시점으로부터 일어나기까지의 시간
그럼 ’latent’ 란?
Latent 라틴어 lateo (숨겨져 있는) 의 현재 분사형인 latens, latentis 로부터 유래. 비활성화 되어있거나, 숨겨져 있음을 나타내는데 사용된다.
이 정의는 꽤 멋진데, 왜냐하면 지연이라는 것이 어떻게 시작되고 영향을 주고 볼수있게 되는지 에 대한 시간간격을 나타내는데 초점을 두고 있기 때문입니다.
예를들어서, 당신이 에어본 바이러스에 감염되어 사람들을 좀비로 만들고 있다고 해봅시다. 이 지연 시간은 당신이 감염되었을때 시작되어 당신이 좀비로 변하는 시간이 됩니다. 이것이 지연입니다: 이미 일어난 어떤것이 숨겨져서 보이지 않는것.
우리 분산시스템이 하나의 큰 작업을 필요로 한다고 생각해봅시다: 시스템의 모든 데이터를 읽어 하나의 결과를 연산해야합니다. 다른 말로 하면, 하나의 분산 시스템을 데이터 저장소로 생각하고 하나의 연산을 해야하는데, 현재 저장된 데이터들에 대해 수행해야 합니다. :
result = query(all data in the system)
어떤일이 일어날까요? 과거데이터가 아니라 현재의 새로운 데이터에 처리되어야한다면요. 사용자에게 보여지기 까지의 시간으로 지연을 측정할 수 있겠습니다.
또 다른 키포인트는, 아무일도 일어나지 않은것에 대한 정의에 기반할 수 있는데, 여기엔 ‘지연시간’이 없습니다.
분산시스템에서, 최소한의 지연은 극복될 수 없습니다: 광속의 한계, 하드웨어 컴포넌트들이 최소한의 지연 비용이 연산마다 있기 때문입니다. (램과 하드드라이브, CPU 도 생각해보세요.)
최소한의 지연시간이 어느 정도냐가 전송되어야하는 물리적거리, 쿼리의 본질에 영향을 받아 당신의 쿼리의 지연시간에 영향을 줄겁니다.
Availability (and fault tolerance)
확장 가능한 시스템에 두번째로 고려해 볼 것은 가용성입니다.
Availablility 기능적인 측면(상태, condition) 에서의 시스템의 시간 비율. 만약 유저가 시스템에 접근할 수 없다면, 가용적이지 않다. 라고 이야기 할 수 있다.
분산 시스템은 하나의 시스템에서 이루기 어려운일을 이룰수 있게 해줍니다. 예를 들면, 하나의 머신으로 구성된 시스템은 실패하거나, 동작하지 않기때문에 (or doesn’t) 어떤 오류에도 tolerant 하지 않습니다.
분산 시스템은 ‘신뢰성 없는 묶음’ 으로 신뢰성 있는 시스템을 만들어냅니다.
불필요하게 장황하지 않은 시스템은 아래 구성되어있는 요소들만큼 가용성이 있습니다. 불필요하게 장황하게 구성된 시스템은 일부의 실패에 대해서도 tolerant 하고, 따라서 더 가용성이 있습니다. ‘불필요하게 장황하다’라는 말이 어떤 시각으로 보느냐에 따라 다른 의미를 가질 수 있겠네요 - 컴포넌트, 서버, 데이터센터, 등등..
공식화해보자면, 가용성이란: Availability = uptime / (uptime + downtime)
기술적인 측면에서 가용성이란, fault tolerant 를 의미합니다. 컴포넌트의 구성 요소들이 늘어남에 따라 실패의 확률이 늘어나기 때문에, 시스템은 컴포넌트의 숫자와 신뢰성이 반비례 하지 않도록 구성되어야합니다.
예를 들어서:
| Availability % | 일년에 downtime 이 얼마나 허용될 수 있을까 ? |
|---|---|
| 90% (one nine) | More Than a month |
| 99% (two nines) | Less than 4 days |
| 99.9 % (three nines) | Less than 9 hours |
| 99.99% (four nines) | Less than an hour |
| 99.999% (five nines) | ~ 5 minues |
| 99.99999% (six nines) | ~ 31 seconds |
가용성은 uptime 이라는 개념보다 더 넓은 개념으로 널리 사용되기도 하는데, 이는 서비스의 가용성은 네트워크의 outage 나 서비스를 책임지는 회사의 영향을 받기 때문입니다. (fault tolerance 와 실질적으로 연관되어있지는 않지만 시스템의 가용성에 영향을 줄 수 있음). 그러나 시스템의 면면을 알고 있지 않으면, 우리가 할 수 있는 건 fault tolerance 겠네요.
fault tolerant 하다는건 어떤 말일까요.
Fault tolerance 시스템에 fault 가 발생했을때 잘정의된 방식으로 동작하는 것
fault tolerance 는 이렇게 정리할 수 있습니다: 어떤 실패가 있을것이라 예상하고 시스템이나 알고리즘을 디자인하는가. 실패를 예상하지 못하면, 고려될 수도 없다.
What prevent us from acheving good things?
분산 시스템은 두 물리적 요소로 인해 제약됩니다.
- 노드의 개수 (요구되는 저장소와 연산 용량에 영향)
- 노드간의 거리 (정보가 전달되기 위함. 최대속도는 광속)
이 제약들 위에서 작업하기 위해:
- 독립된 노드의 수들의 증가는 시스템의 실패율을 올린다. (가용성을 줄이고 운영 비용을 높임)
- 독립된 노드의 수의 증가는 노드들간의 통신 필요성을 높일수 있다. (스케일이 커짐에 따라 성능이 줄어든다.)
- 서로 떨어진 노드들 끼리의 물리적인 거리의 증가는 최소한의 통신지연을 높인다. (어떤 동작들의 퍼포먼스를 저해한다.)
이런 경향들을 넘어서 - 물리적인 제약의 결과 - 는 것이 시스템 디자인의 세계입니다.
퍼포먼스와 가용성 시스템이 구성하는 외부적인 보증에 의해 정의됩니다. 고수준의 시스템에서, SLA (서비스 레벨 동의?) 를 통해 보장되고 있습니다; 데이터를 쓰면, 얼마나 빨리 다른 곳에서 접근할 수 있을까? 데이터가 쓰여지고 나면, 내구성이 있음은 어떻게보 장받을수 있을까 ? 시스템이 연산을 하도록 요청하면, 얼마나 빨리 결과를 돌려줄까 ? 구성 요소가 실패하면, 혹은, 동작에서 제외 되면, 시스템에 어떤 영향을 줄까?
다른 기준이 있는데, 명시적으로 언급되진 않았지만, 내포되어있습니다; 이해성인데, 보장하는 내용이 얼마나 수용가능한가? 물론, 무엇이 수용가능한지 쉽게 정의할 수 있는 단순한 메트릭은 없습니다.
저는 ‘이해성’을 물리적인 제한으로 분류하는 경향이 있습니다. 결국에는, 하드웨어의 제한이 우리가 우리 손가락 이상으로 움직이는 것들을 (외국 속담인듯. 예상이상의 일들을 일컫는것으로 추측된다) 이해하는걸 어렵게 하고 있죠. 에러와 변칙의 차이가 될겁니다 - 에러는 정상적이지 않은 동작, 변칙적인것은 예상치 못한 동작. 만약 당신이 똑똑하다면, 변칙적인 동작도 예상할 수 있을 겁니다.
Abstractions and models
추상화와 모델이 역할을 할 때가 됐군요. 추상화는 문제를 해결하는 데 필요없는 문제들을 제거함으로써 문제를 더 통제할 수 있도록 만들어 줍니다. 모델들은 분산시스템의 속성들의 주요 속성들을 꽤 적합한 매너로 묘사합니다. 다음 챕터에서 더 많은 모델에 대해 다룰 건데, 이런겁니다.
- 시스템 모델 (비동기/동기)
- 실패 모델 (크래쉬-실패, 파티셔닝, 비잔틴)
- 지속성 모델 (강하거나, 이벤트 기반이거나)
좋은 추상화는 시스템을 이해하기 쉽게 만들고, 특정 목적에 관련한 요소들을 제한(capture) 하는데 도움을 줍니다.
많은 노드들과 다른 우리의 욕구.. ‘하나의 시스템처럼 동작’을 유지하는 데에는 긴장이 있습니다. 종종, 우리가 익숙한 대부분은(예를들어 분산시스템에서 추상화된 공유 메모리를 구현하는것) 너무 비용이 많이 듭니다.
더 작은 보장을 할수록, 동작에 대 많은 자유를 보장하고, 잠재적으로 더 높은 퍼포 먼스를 제공하게 됩니다 - 그러나 이것 역시 잠재적으로 이유를 알아내기가 어렵습니다. 사람들은 단일 시스템에 대해 추리(리즈닝)하는 데 더 낫고, 노드들의 집합에는 상대적으로 약하죠.
보통 시스템의 내부에 대해 디테일을 노출하는 것으로 성능을 얻기도 합니다. 예를 들면, columnar storage 에서, 유저는 추측할수 있다. 키밸류 페어의 지역성에 대하여, 그리고 결정할 수 있다.일반적인 쿼리의 성능의 영향성을. 시스템은 이런 디테일을 숨기는 시스템은 더 쉽다 이해하기가. (왜냐하면, 그들은 하나의 단위로 동작하는 것과 같고, 디테일에 대해 생각할 게 더 적다). 반면에 더 실세계의 디테일을 노출하는 것은 더 좋은 수행자다.(실세계에 더 가까우니까)
몇몇의 실패의 유형에서, 단일 시스템으로 구성된것처럼 분산시스템에서 동작하도록 하는 것은 어렵습니다. 네트워크 지연과 네트워크 파티션 (노드들 사이의 모든 네트워크 실패) 은 시스템이 가용하게 유지하지만 어떤 중대한 보장을 강제하지 못하는 것을 감수 할지, 혹은 안전하게, 요청을 거절할지 선택해야할 수 있습니다.
CAP 이론 - 다음 챕터에서 다룰 - 은 이런 긴장을 다룹니다(captures). 마지막에는, 이상적인 시스템은 프로그래머의 필요(클린한 의도)와 비즈니스 요구 (가용성/지속성/지연성). 을 만족시킵니다.
Design techniques: partition and replicate
어떤 데이터 집합이 복수의 노드에 분산되도록 하는 매너는 상당히 어려운 주제 입니다. 어떤 연산이 수행되도록 하기 위해서는, 우리는 데이터를 위치시키고, 여기에 동작할 필요가 있습니다.
데이터 집합에 적용될 수 있는 두가지 기본 테크닉이있는데, 다양한 노드들에 분할 하여, (partitioning) 동시에 실행 될 수 있는 양을 늘리는 겁니다. 이것은 또한 다른 노드에 복사되거나 캐쉬 되어 클라이언트와 서버 사이의 거리를 줄여, 더 큰 fault tolerance 를 얻는 방법이 있습니다. (replication).
Divide and conquer - I mean, partition and replicate.
아래의 그림은 이 두개의 차이점을 보여줍니다.: 파티션데이터 (A 와 B). 독립된 두개집합으로 나뉘었으며, 복제 데이터는 두 위치에 복사되어 위치되어 있습니다.
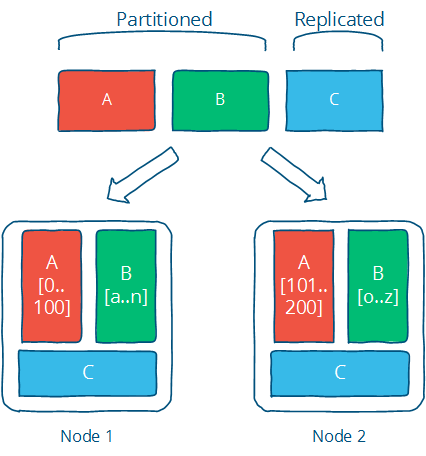
이 것은 분산시스템에서 어떤 문제든 해결하는 원-투 펀치 입니다. 물론, 트릭은 구체적인 구현에 따라 올바른 테크닉을 선택하는 겁니다; 복제와 파티셔닝을 구현하는 많은 알고리즘들이 있고, 각각은 다른 제한과 이점이있어 원하는 디자인 목표를 이루기 위해 적절한 평가가 이뤄져야 합니다.
Partitioning
파티셔닝은 데이터셋을 작은 구분된 집합으로 나눕닙니다; 이것은 데이터 집합의 성장을 줄이는데, 각각의 파티션이 데이터의 서브셋이기 때문입니다.
- 파티셔닝은 측정되어야하는 데이터의 양을 제한하고, 관련한 데이터들을 함께 위치시켜 성능을 증대시킵니다.
- 파티셔닝은 파티션들은 독립적으로 실패하도록 허용함으로써, 가용성을 증대시키고, 가용성이 희생되기 전에 실패해야하는 노드 수를 증가 시킵니다.
파티셔닝은 또한 상당히 어플리케이션 특화되어 있어서, 세부 내용을 알지 못하면 자세히 이야기 할 수 없습니다. 그렇기때문에 복제가 대부분의 문서에서 다뤄지게 됩니다. (이 문서를 포함해서)
파티셔닝은 대부분 당신이 주로 접근하는 패턴이라 생각하는 것에 기반해서 파티션을 정의하게 되며, 독립적인 파티션을 갖게 됨에 따라 오게 되는 제한들을 다루게 되게 됩니다. (e.g. 효율적이지 않은 파티션의 접근, 성장 비율과 다른 비율, 등등 )
Replication
복제는 같은 데이터를 복수의 장비에 위치시킵니다; 이것은 연산에 더 많은 장비가 참여할 수 있도록 합니다.
호머 제이 심슨을 인용해 보겠습니다.
복제를 하기 위해! 모든 인생의 문제의 원인, 해결책이다.
복제 - 복사나 어떤것의 재현 - 은 우리가 지연과 함께 싸울 수 있는 주요한 방법 입니다.
-
복제는 새 데이터의 복사본에 적용가능한 추가적인 컴퓨팅 파워와 대역폭을 통해 추가적인 성능을 얻습니다.
-
복제는 데이터의 복사를 생성함으로써 가용성을 향상시키고, 가용성이 희생 되기 전에 노드의 수를 증가 시킵니다.
복제는 추가적인 대역폭을 제공하는 것이며, 캐싱이 의존하는 형태가 됩니다 이것은 또한 일관성을 유지하며 지속성모델에 따라 유지 합니다.
복제는 확장을, 퍼포먼스를, fault tolerance 를 가능하게 합니다. 가용성의 손실이나 저해된 성능이 걱정되시나요? 데이터를 복제하는것이 한 지점에서의 실패나 병목 현상을 회피 할 수 있게 해줍니다. 낮은 연산? 복수의 시스템에서 연산하도록 복제하세요. 낮은 I/O? 로컬캐쉬를 데이터에 적용하여 지연을 줄이거나 복수의 장비에 적용하여 대역폭을 증대시킬 수 있도록 복제하세요.
복제는 또한 많은 문제들의 원인이기도 한데, 복사된 데이터들은 이제 독립적이기때문에, 동기화가 이뤄져야하기 때문입니다 - 이것은 복제가 일관성 모델을 따라야함을 의미합니다.
일관성 모델을 선택하는 것은 중대합니다: 좋은 일관성 모델은 프로그래머에게 간결한 의미를 제공합니다. (다른 말로하면, 이해하기 쉬운 형태로 유지가 된다는 이야기힙니다.) 또한 고가용성/강력한 일관성에 대한 비지니스/디자인 목표를 충족합니다.
복제에 대한 하나의 일관성 모델 - 강력한 일관성 - 은 프로그램이 복제되지 않은 것 처럼 동작하게 합니다. 다른 일관성 모델은 내부적인 처리를 프로그래머가 감안하도록 합니다. 그러나, 더 약한 일관성 모델룰 수록 낮은 지연과 높은 가용성을 제공합니다 - 그리고 이해하기 어려운것이 아니라, 다를 뿐입니다.